|

5款芯片已经面世,可重构架构是AI芯片的新风潮?
新的方法、新的思维、新的目标一直引领着新的浪潮。2017年的两位图灵奖得主John L. Hennessy 和 David A. Patterson在年初的一篇报告中展望,未来的十年将是计算机体系架构领域的“新的黄金十年”。
AI的发展更加期待新架构的出现,因为,经典的冯诺依曼架构处理器应用于深度学习计算时面临着内存墙挑战(访问存储器的速度无法跟上运算器消耗数据的速度)。粗粒度可重构架构(CGRA,Coarse Grain Reconfigurable Architecture)是AI芯片受关注的一个方向,目前已经有5款采用该技术的芯片推出。
可重构是否是解决AI计算挑战的一个好方向?已经推出的可重构AI芯片有何不同?
?
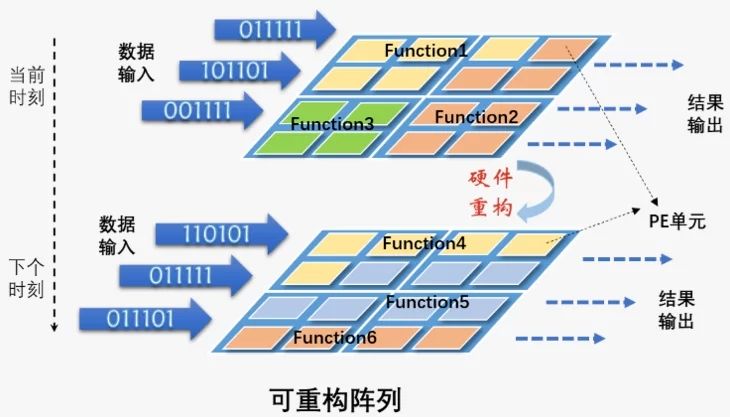
什么是可重构?
可重构的概念最早在20世纪60年代被提出。到了80、90年代,可重构芯片技术源头的高层次综合理论和方法诞生。进入新的世纪,2015年国际半导体技术发展路线图(ITRS)认为,粗颗粒度可重构架构(CGRA)是未来最有发展前途的新兴计算架构之一。
2018年,美国DARPA正式启动旨在支撑美国2025-2030年电子技术能力的“电子复兴计划”(ERI),提到研发具有软件和硬件双编程能力,并获得接近专用电路性能的技术。在这里领域,魏少军教授牵头的清华大学可重构芯片课题组在这个计划提出的十年前就开始了研究,课题组现在的成果比ERI设定关键性能的指标更高。
从60年前可重构概念的提出,到2019年有可重构AI芯片量产,可重构并不是一个新概念,却是一个挑战众多的技术。这种挑战很大程度来源于,动态可重构芯片既要有CPU和GPU级别的软件可编程性,也要有FPGA级别的硬件可编程性。
魏少军教授总结认为动态可重构芯片预期的特点和潜在能力区别于传统芯片有7点:
(1)软硬件可编程;
(2)硬件架构的动态可变性及高效的架构变换能力;
(3)兼具高计算效率和高能量效率;
(4)本征安全性;
(5)应用简便性,不需要芯片设计的知识和能力;
(6)软件定义芯片;
(7)实现智能的能力。
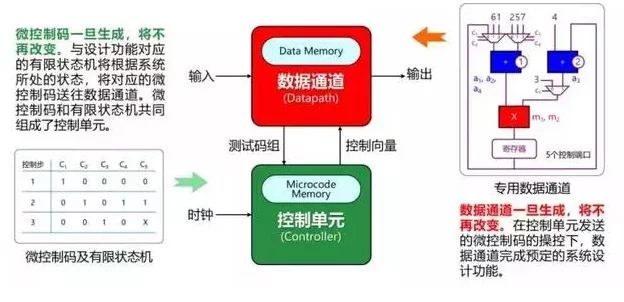
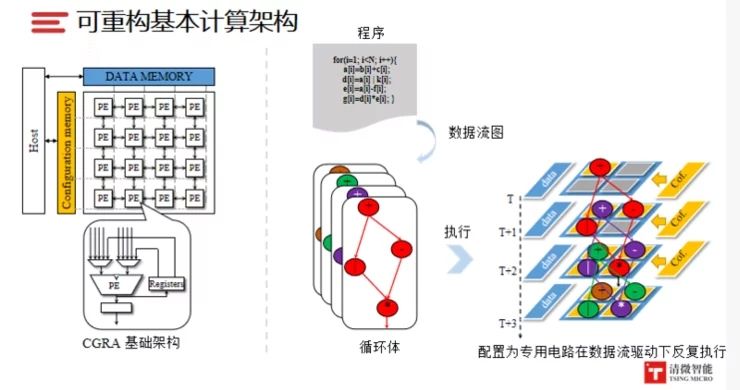
可重构芯片的技术的源头高层次综合(High-LevelSynthesis)理论和方法,是一种从行为描述到电路的优化设计方法。也就是先找到数据依赖关系,然后通过运行时间的分割,对运算进行调度来实现计算资源的复用。
高层次综合生成的专用集成电路架构
用高层次综合系统的实现过程进行更具体的解释,系统输入用硬件描述语言(HDL)写成的系统行为描述(如VHDL或Verilog),然后根据这些行为描述,通过高层次综合的编译器,生成包含数据和互连网络配置信息的微控制码以及与系统功能相关的有限状态机。
不过,这里所说的“编译器”与传统的计算机的编译器并没有任何关系,只是借用编译器的概念,其核心是一整套高层次综合方法学的内容。
高层次综合系统使设计过程变得非常有序,也被认为是20世纪80、90年代集成电路设计方法学中最好的选择。
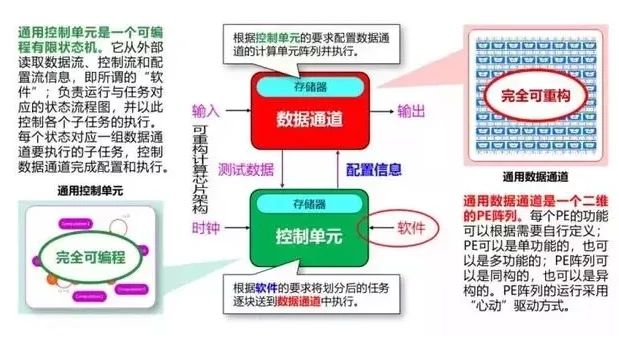
可重构芯片的基本架构
不过,半导体制程技术的演进也带来了高成本的问题。如果研发一款14nm制程的芯片,综合成本高达1.5-2亿美元,通常要销售3000万颗以上才能把研发成本合理地摊销到每颗芯片上。如果采用目前最先进的7nm制程的芯片,综合成本可能高达3亿甚至更多。芯片的设计和制造成本在增加,但AI对算力的需求也在按月增加。
这时候,复用芯片是个不错的选择。设想一下,相同的芯片,功能可通过软件改变,不同的软件写入就变成了“专用”芯片。这将是非常理想的情况,如果这个想法实现,可以认为软件定义芯片就成为了现实。
但挑战在于,软件可以无限复杂,执行时间可以无穷长,硬件不管多大都有边界。可重构芯片业面临众多挑战,其中有三个主要的挑战:
计算模式:如何提高阵列利用率?
阵列结构:如何提高计算能效?
算法映射:如何优化映射效率?
可重构技术的优势和挑战都同样显著,采用这个技术,清微智能、耐能、云天励飞、燧原科技、WaveComputing相继推出了AI芯片,他们有何不同?
5款可重构AI芯片面世
清微智能
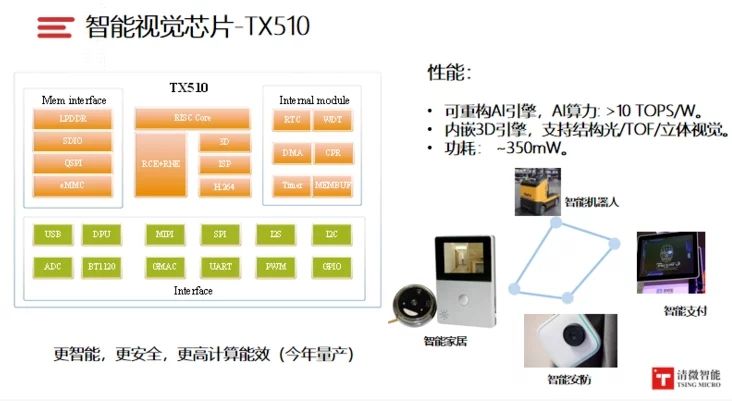
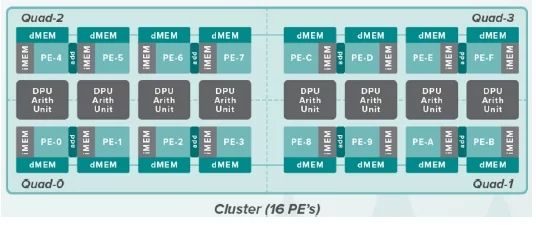
清微智的核心成员来自清华大学可重构计算研究团队,2019年量产的首颗芯片是TX210,这款语音SoC芯片可以应用于智能手机、可穿戴智能设备、小家电、大家电、玩具、车载等场景。清微的可重构芯片主要分为三个维度,从MAC层面支持不同的位宽重构,到执行单元层面支持不同算子重构,再到阵列层面支持不同功能重构。
用一个更容易理解的类比来解释清微可重构芯片的可重构程度,清微的可重构芯片既可以是“乐高”层级的可重构,也可以是“面粉”层级的可重构。
清微智能CTO欧阳鹏此前接受雷锋网采访时透露,在可重构计算更低能耗和更强灵活性的基础上,他们在具体的芯片设计上又做了两方面深化。
清微的AI芯片支持从1bit-16bit的混合精度计算,同时,不同的神经网络层可以采用不同的精度表示,可实现实时切换精度。在具体实现过程中,可重构模式动态重组计算资源和带宽,根据精度表示,让计算资源和带宽接近满负荷进行计算,从而将混合精度网络下的计算资源和带宽的利用率逼近极限,高效支持多种混合精度的神经网络。
另外,清微的AI芯片针对神经网络部分和非神经网络均进行了计算效率考虑。针对非神经网络处理逻辑,从算法数据流图进行空间映射,以接近ASIC效率计算。同时,通过配置形成不同的电路结构来动态处理不同非神经网络计算逻辑,在保证灵活性前提下,计算效率有极大提升。
需要指出,可重构芯片代表的是采用的是数据驱动下的空域执行模式,区别于CPU、GPU、NPU诺依曼架构的时域计算模式,数据流驱动的芯片从架构上就可以避免了冯诺依曼架构的限制。
目前,清微智能除了可重构架构的语音芯片,还发布了面向智能家居、智能安防和新零售领域的低功耗图像识别芯片。
云天励飞
云天励飞没有具体解释其芯片中的可重构架构,云天励飞副总裁 芯片产品线负责人李爱军在接受雷锋网采访时表示,云天的实现方式是从PE的维度进行可重构,可以理解为运算单元的可重构,通过工具链实现芯片的灵活性。因此,采用的方式和维度会有所不同(与清微相比),但最终的效果应该是异曲同工。
在其今年11月发布的专注边缘和端侧视觉新产品DeepEye1000介绍中提到,采用存算融合体系架构和可重构计算阵列,可以灵活、高效的执行各种深度学习算法模型的推理计算,峰值算力达2.0Tops。
神经网络处理器采用可重构计算阵列,支持灵活可编程计算流,计算效率超过99%,同时采用存算融合体系架构,使得DDR存储访问带宽下降77%,功耗下降60%。
更多的技术细节,需要云天励飞进一步披露。
耐能
耐能今年5月在国内发布物联网专用AI SoC——KL520时表示这款新品使用了可重组架构,虽然不是可重构技术,但两者之间同样存在关联。还是用上面的类比来解释,耐能的架构是积木层级的可重组,清微智能的可重构则是面粉层级的可重组,更加底层。
耐能CEO刘峻诚解释,可重组架构可以理解为这款芯片提供的是一堆乐高积木,需要支持语音AI的模型时就通过指令集进行组合,需要支持图像AI模型时,再重新组合,可以很好地支持多种神经网络模型,并且保持架构的精简性。
由此能够带来性能和功耗的优势,如果选用更加成熟的工艺制程,降低成本,最终能实现高性能、低成本、低功耗、高兼容性的优势。
另外,可重组架构还能动态支持同一个神经网络的不同数据精度需求。最终产品可以根据客户的需求,支持Int8、FP16或更高的精度。压缩率也能够控制在0.5%以内则是来源于耐能独特的开放平台,通过这个开放平台能够将压缩率提升40甚至50倍,压缩率损失则小于0.5%,这是软件或者说软硬一体优势的体现。
据悉,耐能的可重组架构研究已经在国际知名的半导体期刊上发布,并且在美国、台湾都拿到了专利。
燧原科技
除了将可重构的理念和技术应用于边缘端,同样是国内初创公司的燧原科技在其云端训练AI芯片中也用到了可重构。
燧原科技的首款芯片邃思DTU基于可重构芯片的设计理念,其计算核心包含32个通用可扩展神经元处理器(SIP),每8个SIP组合成1个可扩展智能计算群(SIC)。SIC之间通过HBM实现高速互联,通过片上调度算法,数据在搬迁中完成计算,实现SIP利用率最大化。
如何理解DTU中的可重构芯片设计理念?燧原科技创始人兼 COO 张亚林告诉雷锋网,“端上的可重构更多是低功耗以及可以轻易移植应用。云端的可重构主要的是把整个数学计算变成一种可编程的指令集和可控的流水线,让数学计算的模型可以重构,这样可以保证芯片的通用性,也能够适应快速迭代的AI算法。”
更进一步的细节目前也暂不清楚。
Wave Computing
国内采用可重构技术的AI芯片不少,国外初创公司Wave Computing的AI芯片也采用该技术。其基于数据流驱动DataFlow技术的DPU采用非冯诺依曼架构的软件可动态重构处理器CGRA技术,能在最合理分配和使用算力的同时,成倍节约了数据存储和传输带宽。官方表示,这一方案基本上能将芯片算力资源的利用效率保证在75%-80%以上。
具体而言,DPU对一个完整的神经网络计算流程,每个计算节点,可以先分配好合理的资源,使得整个计算流程达到资源有效地使用。处理完第一个任务节点,它会将数据直接传输到第二个任务节点的输入端,第二个任务处理完数据后,又会将任务送到第三个任务节点的输入端,就像流水线,最大程度减少数据存储和传输。
同时, DataFlow技术架构的整体解决方案会有一个独立的通用CPU模组来提供控制、管理和数据预处理功能,但无需实时干预DPU。
目前,Wave Computing商用的DPU采用16nm制程工艺,每个DPU有16384个处理元件(PE),面积为300多平方毫米,并以6 GHz以上的速度运行。其DPU与国内外多家云服务商和AI公司均有紧密合作,合适汽车电子、智慧医疗等各种复杂、算力要求高的各类AI应用。
无论是国外还是国内,无论是云端还是终端,都有采用可重构技术的AI芯片已经推出,这表明可重构技术无疑是业界关注的一个新技术。但各家对技术的理解和应用也有差别,从目前的信息看,清微智能对该技术做了更深入的解读,Wave Computing也发布文章解释其DTU,云天励飞、耐能、燧原科技还没更进一步的技术解读。
理想的可重构不仅能够满足不断迭代的AI算法以及各种应用的需求,软件定义芯片的方式也能尽可能延长芯片的使用时间,但实现理想的可重构芯片仍然还有许多挑战。
版权声明:
本站部分内容、观点、图片、文字、视频来自网络,仅供大家学习和交流,真实性、完整性、及时性本站不作任何保证或承诺。如果本站有涉及侵犯您的版权、著作权、肖像权的内容,请联系我们(021-62511200),我们会立即审核并处理。
|
|||||||||||||||